缘由
我们在大数据数据里面有一类数据是 域名,例如 www.jixuejima.cn ,我们需要把 cn 和 jixuejima.cn 提取处理,这个其实就是TLD(TOP LEVEL DOMAIN)顶级域名解析过程。
大家看过我们前面ELK相关文章的,都知道我们处理过程是 FileBeat -> Redis -> LogStash -> ES 。在 聊聊公司的技术栈 这篇文章中我就说过这个过程,但是肯定很多人很郁闷,为什么不能直接从FileBeat 直接 到 ES。其实就是因为原始数据要结果处理之后才能进入ES,而FileBeat处理能力是有限并且是非常差的(至少我们在使用过程中发现就是这样的一个结果)。
解决方案
logstash有很多插件可以用,找了很久发现了一个 : https://github.com/logstash-plugins/logstash-filter-tld 。这个logstash插件可以解决我的需求。
安装
/usr/share/logstash/bin/logstash-plugin install logstash-filter-tld
配置
在logstash的配置中filter里面加入如下配置
tld {
source => "domain"
add_field => [ "main_domain", "%{[tld][domain]}" ]
add_field => [ "domain_suffix", "%{[tld][tld]}" ]
}
tld插件有如下几个字段
tld.domain jixuejima.cn
tld.sld jixuejima
tld.subdomain www.jixuejima.cn
tld.tld cn
tld.trd www
效果展示
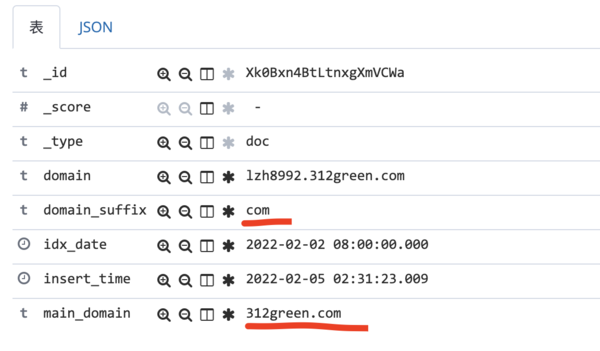
题外话
在找需求的解决方案的过程中发现了一个PSL(public suffix list 公共域名后缀列表),这个是TLD的基础。所以我在服务器里面的插件也找到了对应的PSL文件:/usr/share/logstash/vendor/bundle/jruby/2.5.0/gems/public_suffix-1.4.6/lib/definitions.txt(由于logstash tld是ruby写的,所以在ruby的目录里面的)





不错
回复 @ apanly: 非常不错